EVM Memory

smart contract developer
Hello, and nice to see you again. I hope you enjoyed the last write-up on Ethereum virtual machines (EVM) in simple terms.
Today, we will be talking about memory, as promised last time. We are going to be seeing, in the simplest way, what memory is.
Understanding Memory in Ethereum's EVM

Recall that in the previous post, we said memory is like a short-term notepad used for calculations. Picture the EVM having a big notepad that it can write on and erase. This notepad, called "Memory," is like a temporary workspace for doing calculations. When the EVM needs to do math or store intermediate results, it writes them on this notepad. Once the task is done, the notepad gets wiped clean.
What is memory?
Memory is quick, temporary storage. It is quick to write on and erase, but it's not meant for keeping things long-term. It is also used for complex operations. When smart contracts perform complex calculations, they might use memory to store and manipulate data. Remember, memory is different from storage. Storage is like a more permanent file cabinet (we will see this in a bit); memory is more like a notepad, 📒 you use for quick, temporary stuff.
Memory is a byte array that starts at zero. Just like our notepad analogy, imagine the notepad starting empty—no size or content. Fortunately, the EVM can enlarge this page in 32-byte increments as needed. If the EVM accesses or stores data beyond the current size of the page, it automatically makes the page larger in 32-byte pieces. Memory is expandable and contiguous. Instead of having big areas of zeros, memory is contiguous, which saves gas by keeping it packed and decreasing in size. It's more efficient to keep it packed, minimizing unused spaces and large patches of zeros. This efficiency helps save gas, making operations more cost-effective. The more efficient, the better!
MLOAD
Let's say you need to read a whole page of information. MLOAD is like grabbing an entire page from the notepad and showing it to someone. It loads 32 bytes from memory into your stack.
Diagram depicting MLOAD
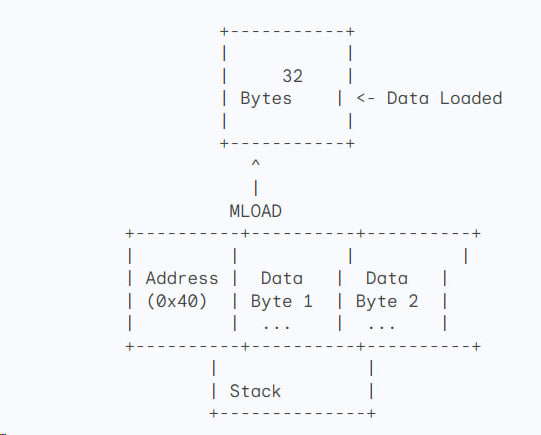
Before MLOAD

MLOAD instruction
After MLOAD

MSTORE
Now, you have some important notes, and you want to save them to this current notepad. MSTORE is the way. It's like copying an entire page. It saves a whole word from your stack into memory.
Diagram depicting the MSTORE
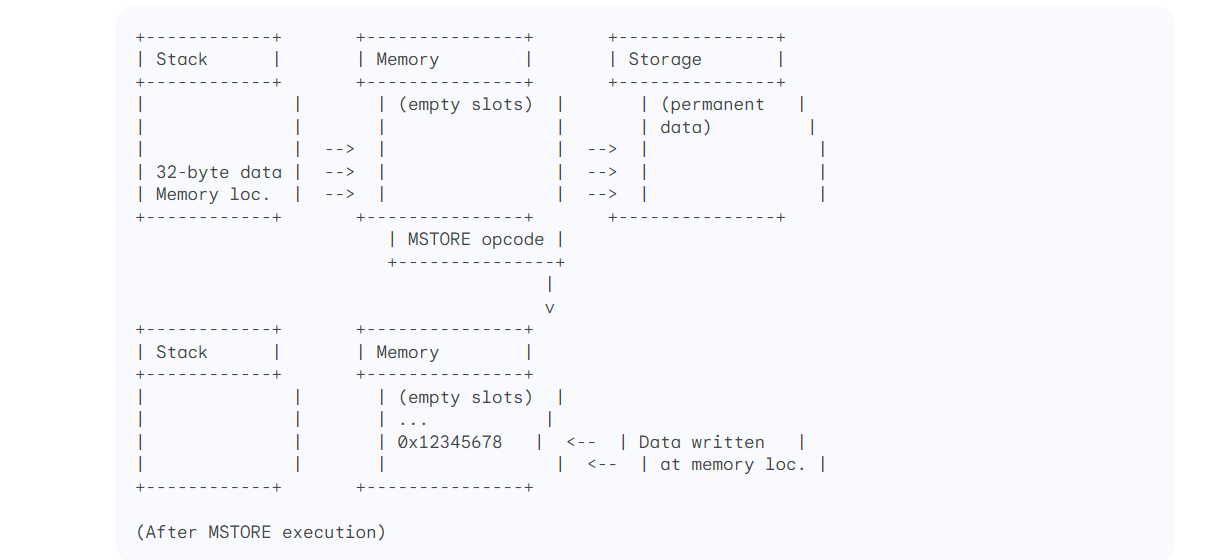
Explanation of the MSTORE Diagram
The stack initially has two elements:
32-byte data: This is the value you want to write to memory.
Memory location: This is the starting address where you want to write the data.
The
MSTOREopcode is executed.The 32-byte data and memory location are popped from the stack.
The memory location acts as the address of the "mailbox" in memory.
The 32-byte data is written into the specified memory slots, starting at the provided address.
MSTORE8
If you only care about a tiny piece of information (just one byte), MSTORE8 is your friend. It saves a single byte to memory.
Diagram depicting the step-by-step execution of MSTORE8 using arrows to show the flow of data
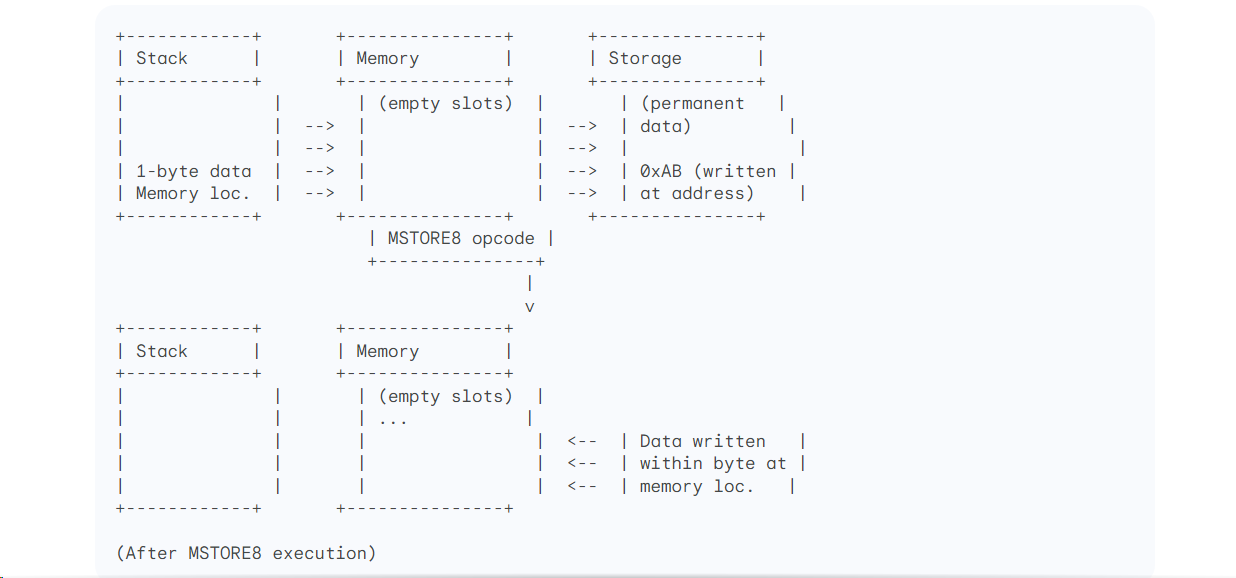
Explanation OF THE MSTORE8 diagram
The stack initially has two elements:
1-byte data: This is the value you want to write to memory.
Memory location: This is the starting address where you want to write the data.
The
MSTORE8opcode is executed.The 1-byte data and memory location are popped from the stack.
The memory location acts as the address of the byte within a 32-byte word in memory.
The 1-byte data is written into the specified byte within the word at the provided address.
Diagram focusing on the state transitions involved in MSTORE8 execution
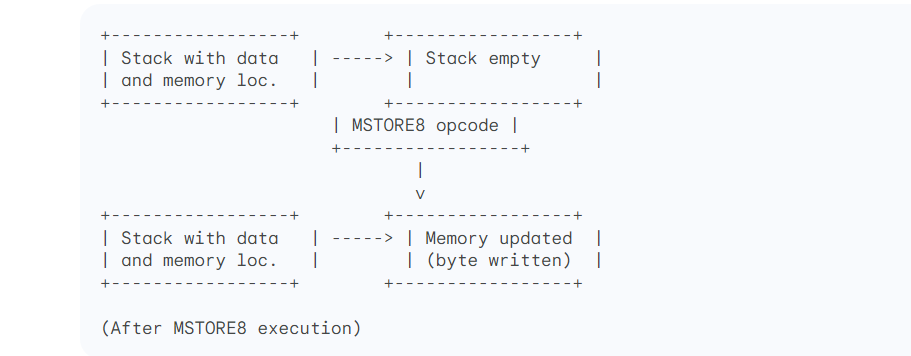
Explanation of the diagram focusing on the state transitions involved in MSTORE8 execution
The diagram starts with the stack, which contains both the data and memory locations.
The
MSTORE8opcode transition represents the operation of writing the data to a single byte within a memory word.The final state shows the stack emptied and the memory updated with the written byte within the specified word.
Memory Expansion
You are responsible for paying for the number of bytes that your contract writes to memory. For the first time, there is an additional memory expansion cost when writing to a section of memory that has never been written to previously. When writing to previously unoccupied memory space, memory is increased in increments of 32 bytes (256 bits), as said previously.
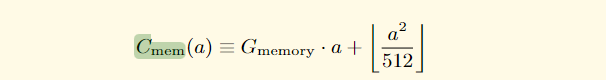
For the first 724 bytes, memory expansion costs scale linearly. Imagine you have a ruler, and each inch on the ruler represents an increase in memory. If you need 1 inch of memory, it costs $1. If you need 2 inches, it costs $2. So, the cost increases in a straight line, or linearly, with the amount of memory you're using, but only up to the first 724 bytes.
After the first 724 bytes, it goes quadratically. Now, let's say you need more than 724 bytes. After reaching 724 bytes, the cost doesn't increase in a straight line anymore; it starts going up much faster. It's like if you needed 3 inches of memory, it won't cost $3; it might cost $9 (3 squared). The cost starts increasing exponentially, or quadratically, making it more expensive as you use more memory beyond 724 bytes.
There is zero cost for the second part if using <= 724 bytes. If you're using 724 bytes or less, the second part of the equation (the quadratic scaling) is not applicable. So, for the first 724 bytes, it's as if the quadratic scaling doesn't exist, and the cost is simply based on the linear scaling.
All there is to the above is like paying a certain amount for the memory you use, but if you go beyond a certain point (724 bytes), the cost starts increasing much faster than before. If you stay within the first 724 bytes, the extra, more expensive part doesn't come into play, and the cost behaves more predictably.
Ethereum yellow paper...
Note also that Cmem is the memory cost function (the expansion function being the difference between the cost before and after). It is a polynomial, with the higher-order coefficient divided and floored, and thus linear up to 704B of memory used, after which it costs substantially more.
You can check out the Ethereum yellow paper here.
Still using our "notepad" analogy, Think of memory like a notepad where you jot down numbers and notes. Each page on the notepad is like a byte, and each line on the page is like a bit. This notepad is where you keep temporary information while doing calculations. Unlike having to write on specific sections of the notepad, you can start writing or reading from any point. It's like you don't have to follow the lines or start from the top; you can scribble anywhere on the notepad.
We are not constrained to multiples of 32. There is no need for multiples of 32. You're not restricted to writing only on every 32nd line; you can write on any line. It's like you can use the notepad freely without being confined to specific blocks or sections.
Memory is linear. Using our notepad, the notepad is organized in a straight line. If you start writing on one side and move to the other, you go through each line one after the other. It's like reading a story from left to right. Each line on the notepad has its number, just like each byte in memory has its unique address. So, when you want to look at or change a specific piece of information, you refer to it by its line number, which is at the byte level.
If you need more space to work out a problem, you can create a new page on the notepad. This happens when you're doing a specific task, like solving a math problem (function). You can make new pages (allocate memory) to write down more numbers. These new pages can be for completely new calculations (newly instantiated complex types like arrays and structs) or copies of information you already have on another notepad (storage-referenced variables). It's like either starting fresh or taking a piece of information from another notepad and bringing it into your current work.
More points for us 😊
The EVM's memory is a linear array of 32-byte slots, each with a unique address.
Memory is temporary and not saved after contract execution. Use storage for permanent data.
MLOADonly operates on memory, not storage.MLOADplays a crucial role in handling dynamic data structures and complex computations within the EVM and It's often used in conjunction with other memory-related opcodes likeMSTOREandMSTORE8.MSTOREis a fundamental opcode used in various smart contract operations like data manipulation and function calls.MSTOREonly works with 32-byte values. For smaller data, useMSTORE8.MSTOREoverwrites any existing data at the specified memory addresses.- In
MSTORE, data is stored word-wise, meaning a byte array might span multiple words depending on its size. You can access the stored data using other opcodes likeMLOAD, which takes the memory address as input and returns the corresponding word.
- In
MSTOREis a gas-intensive operation, so efficient memory management is crucial in smart contracts.Other
MSTOREvariants likeMSTORE8andMSTORE32exist for storing specific data types more efficiently.Remember that
MSTORE8only works with 1-byte values.
Wow... I hope I was able to break this down to its simplest form.
I will see you next time when we talk about storage.
You can check my blog homepage to see more beautiful articles. Also, we can meet on LinkedIn, Twitter, and Github.
See you next time! 😊




